Deep Research: A Stepping Stone Toward AGI — Getting Hands-On with Cross-Business Agentic Use Cases
I’ve been experimenting with Deep Research agents—autonomous AI systems that plan, search, and synthesize information across multiple business domains. Using the OpenAI Agents SDK and tools like WebSearchTool, FileSearchTool, and ComputerTool, I’ve built multi-agent workflows that deliver structured, actionable insights at speed. These experiments hint at a future where agentic systems aren’t just assistants, but cross-domain collaborators—bringing us a step closer to AGI.
Jeff Barnette
8/2/20257 min read


In my career as a senior software engineer, I’ve been fortunate to witness—and contribute to—some of the most transformative moments in our field. Cloud computing, CI/CD, large-scale distributed systems, deep learning, transformer architectures… each of these breakthroughs felt huge at the time. But in the past few months, I’ve been diving into something that feels different. Not just an evolution in tooling or a marginal increase in capability, but a fundamental shift in how software thinks and works for us: Deep Research Agents.
It’s a concept I believe is going to be one of the key stepping stones toward Artificial General Intelligence (AGI). And right now, I’m in the middle of experimenting with it—not just in isolated AI sandbox demos, but in cross-business, real-world, agentic use cases that cut across silos and reshape how we execute work.
This post is both a reflection on what I’m doing and why I think it matters, as well as a behind-the-scenes look at how these agents work and what their commercial implications might be.
Why Deep Research Matters in the AGI Journey
If you follow AI progress closely, you’ve probably noticed two parallel threads:
Models are becoming more capable in their general reasoning, synthesis, and understanding
The ecosystem around them—tools, APIs, agents—is evolving to let them act in the world.
Deep Research agents sit at the intersection of these two trends. They’re not just passively responding to queries like a search engine. They’re actively planning multi-step reasoning chains, selecting the right tools, adapting their approach mid-stream, and then delivering structured, actionable output.
That active, goal-directed nature is the essence of agency. And in my view, it’s what will carry us from today’s LLM-powered assistants to true AGI systems that can autonomously pursue complex objectives.
Cross-Business Agentic Use Cases: Why This Is Huge
A lot of AI demos still live in single-domain bubbles: customer support bots, code assistants, marketing copy generators. That’s fine for showing off capabilities, but the real value starts when you break down the walls between business units.
That’s where my current work comes in.
I’ve been experimenting with cross-business agentic workflows—where a single agent or a team of agents can operate across finance, operations, sales, compliance, and engineering—pulling together data, synthesizing knowledge, and producing outputs that any department can use.
Imagine this:
A research agent pulls financial filings, competitive intelligence, and regulatory updates from multiple sources.
It then sends structured findings to a planner agent that determines what actions each department should take.
That planner coordinates with specialized agents—one for generating reports, another for creating technical tasks in Jira or Linear, another for emailing stakeholders.
That’s not just task automation—it’s autonomous cross-domain problem-solving.
In my day-to-day, I’ve found these workflows incredibly powerful. Instead of manually hunting for data, parsing it, and reformatting it for each audience, I can set up an agentic chain that handles it end-to-end. I can focus on higher-order thinking while the agents handle the grunt work.
Commercial Implications: Why Businesses Should Pay Attention
From a commercial perspective, Deep Research agents have three killer properties:
Universality — Almost every knowledge-heavy process in a business involves some form of research, synthesis, and communication. These agents are domain-agnostic, meaning the same underlying architecture can serve HR, marketing, legal, and engineering without major rewrites.
Speed & Scale — What would take a human team days or weeks can be executed in minutes—without compromising quality. This is especially impactful in competitive markets where being first to insight is a game-changer.
Quality & Auditability — With structured outputs and traceable execution (more on that later), you can audit the reasoning steps, verify sources, and iterate on the workflow with precision. This is critical for regulated industries.
The cost/benefit ratio here is striking. In early experiments, I’ve seen processes that used to require dozens of emails and multiple review meetings be reduced to a single run of a multi-agent plan. And because these agents are modular, you can easily reconfigure them for new objectives.
Experimenting with the OpenAI Agents SDK
The infrastructure making this possible in my work is the OpenAI Agents SDK—a platform that makes it remarkably straightforward to spin up goal-directed AI agents, equip them with tools, and chain them together into complex workflows.
Here’s a high-level look at my setup:
planner_agent — This is the conductor of the orchestra. It takes the overall research goal, breaks it down into tasks, assigns those tasks to specialized agents, and determines when the workflow is complete.
search_agent — This is the boots-on-the-ground researcher. It uses tools like WebSearchTool and FileSearchTool to gather relevant data, both from the open web and from internal knowledge bases.
report_agent — Once the data is in, this agent transforms it into structured outputs, often JSON schemas or other machine-readable formats, so downstream systems can act on it.
writer_agent — Takes the gathered and processed research data and produces a clear, well-structured report tailored to the original query’s requirements.
email_agent — Finally, the results get communicated to stakeholders in a polished format.
And the best part? With the SDK, each of these agents can be configured to automatically call hosted tools like:
WebSearchTool — For external knowledge gathering
FileSearchTool — For internal repository searches
ComputerTool — For executing code or automating local/system tasks
In my experiments, these tools integrate so seamlessly that the agents can mix them within a single reasoning chain—e.g., find relevant web documents, cross-check them with internal files, then run a small Python script to analyze the combined dataset.
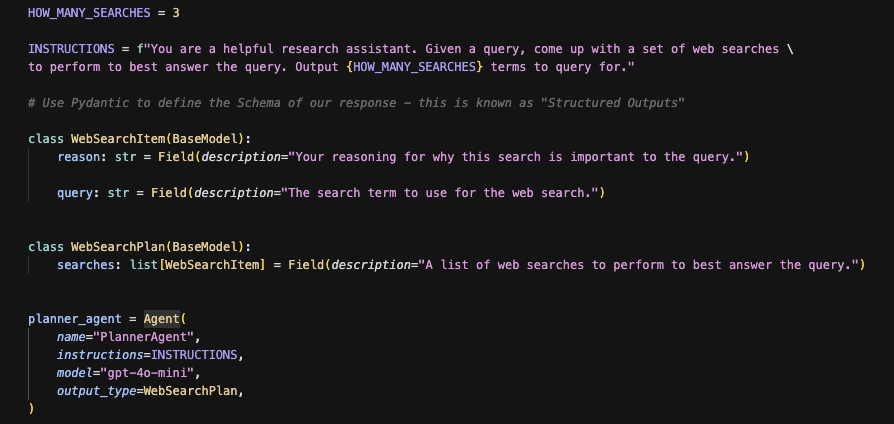
Structured Outputs: The Glue That Holds It Together
One of the most underrated aspects of this workflow is the use of structured outputs.
It’s tempting to think of AI output as “text” or “natural language,” but when agents talk to each other—or feed results into downstream systems—you need something more formal. That’s where structured outputs come in.
Instead of spitting out paragraphs, agents return objects with explicit fields, like:
This makes it trivial to plug the output into another agent, a dashboard, or even a non-AI system. It also dramatically reduces the ambiguity that comes with pure text responses.
Multi-Agent Planning & Execution
One of the core patterns I’m using is planner-executor architecture.
The planner_agent is responsible for deciding the sequence of steps, assigning tasks to specialized agents, and coordinating the flow of information. The search_agent focuses entirely on data gathering, without worrying about the broader strategy.
Once the planner is satisfied with the data, it hands it off to the report_agent, which formats it according to the structured output schema. Finally, the email_agent packages the report for distribution.
Sometimes we use a “two function stop” approach:
Function 1: Write the report.
Function 2: Email it.
By cleanly separating these, we can verify and adjust the report before it’s sent—keeping humans in the loop where needed.
Observing Agent Behavior with OpenAI Traces
When you’re working with multi-agent systems, visibility is everything. If something goes wrong—or even if it works perfectly—you want to know why the agents made the choices they did.
This is where OpenAI Traces comes in.
With Traces, I can:
Watch each reasoning step in detail
See which tools were called, with what arguments
View intermediate results and how they influenced later steps
Debug errors quickly by pinpointing where the reasoning chain broke
This level of transparency is a massive confidence booster, both for me as a developer and for business stakeholders who want to trust the system.
Day-to-Day Applications
On a personal level, Deep Research agents have started to seep into my everyday work.
For example:
Code Audits — The agents can pull in PR histories, related documentation, and commit messages, then summarize risks or suggest improvements.
Competitive Analysis — Instead of manually scanning tech blogs, product pages, and patents, I just give the agent a target company and let it compile a full brief.
Meeting Prep — They can search across internal Slack, Jira, and Google Drive to build a pre-read packet before a call.
The beauty is that the same architecture can handle all these cases, simply by swapping out the prompts, structured output schema, and any domain-specific constraints.
Early Lessons Learned
Through my experimentation, a few key takeaways have emerged:
Tool choice matters as much as the model. The same model behaves very differently depending on which tools it can access.
Structured outputs are not optional. They are essential for reliability and chaining.
Planner agents are worth the overhead. Even in small workflows, having a dedicated planner improves clarity and maintainability.
Transparency is a selling point. Stakeholders love being able to peek into Traces and see exactly how an answer was formed.
Where This Is Headed
I genuinely believe Deep Research agents are going to become a default layer in enterprise AI stacks. They’ll be:
The first touchpoint for knowledge retrieval.
The orchestrator for multi-system workflows.
The bridge between human decision-makers and automated execution.
And as they get more capable—reasoning more abstractly, working over longer time horizons—they’ll start to look and feel like proto-AGI systems.
Right now, we’re still in the early days. The workflows I’ve built aren’t perfect. The agents still occasionally go off track. But the trajectory is clear. We’re moving from “chatbots” to “colleagues.”
See It for Yourself
If you’re curious to see the code behind these experiments, I’ve made it available here:
https://github.com/jeffbarnette/Deep_Research
You’ll find:
Agent definitions
Tool configurations
Structured output schemas
Orchestration logic
Final Thoughts
Working with Deep Research agents has been one of the most exciting phases of my career. It’s not just about building faster or scaling further—it’s about creating systems that can think, plan, and execute in ways that start to resemble human-level problem-solving.
We’re not at AGI yet. But if you squint really hard, you can see the shape of it in these Agentic workflows. And when you give these agents the ability to move fluidly across business domains, you get a glimpse of what work could look like in the not-so-distant future.
Right now, these systems are augmenting me. Soon, they’ll be augmenting entire organizations. And eventually? They’ll be collaborating with us on the most complex challenges humanity faces.
If that’s not a stepping stone toward AGI, I don’t know what is.